
Rock solid pipeline - how to deploy to production comfortably?
First of all, this post won’t be for people who think developer’s job is to design, write code and test it. It’s far beyond that. One of the important responsibilities is to ship your code to production. How to do that safely?
Starting with the artifacts
Where do we begin? Assume you designed, wrote the code, tested it, reviewed it, wrote integration tests, added logging, metrics, created documentation, updated dependencies/libraries, pushed the code to some kind of a repository (doesn’t matter which one) and your build system created runnable version of your code with the all needed content – you have the ARTIFACTS for the deployments. So now what?
For deployment and code validation purposes we use a pipeline. It’s a series of verification steps which ensure our code is working as required. How many stages should the pipeline have? What stages should it have?
 A pipeline.
[Edit it on draw.io](https://www.draw.io/?lightbox=1&highlight=0000ff&edit=_blank&layers=1&nav=1&title=a%20pipeline#R5ZbBcoIwEIafhmNnIlFLj5WKvfTkoecIC2QMLBOjaJ%2B%2BQTcCQzv1UutYLiT%2FbjbJt%2F8hHg%2BL%2FUKLKn%2FDBJTns2Tv8RfP90f%2BmNlfoxycMp2elEzLhLRWWMoPIJEWZluZwKaXaBCVkVVfjLEsITY9TWiNdT8tRdXftRIZDIRlLNRQfZeJyUkdMdYGXkFmOW0dTCiwEvE607gtaT%2FP5%2BnxO4UL4WpR%2FiYXCdYdic89HmpEcxoV%2BxBUA9dhO62Lvomez62hNJcsmDymMBUriFmQsnG8eqAKO6G2xMLjEZ3VHBwfe%2ByqGW4MVB6f1bk0sKxE3Gi19YTVclMoOxvZYYqloR77QTOXSoWoUB%2BLccYCFkWU19Gj42f1jdG4BhcpsbSVZsObuqODNrDvSHTzBWABRh9sirOla2fd9pg7C%2Bbd9pImyFbZuVSL1g6I7oWk%2FQHpBHagsCqaG90ZcYqeSd5EB%2Fh%2F8DpFJ9MLyLNrkR8PyFcak21sJJZWn91pEwL%2Bh%2FYfur3H%2FPl2mQ8Af9GGn5lfg%2FEPvg7vnbHz9dPk15jbafs8OsY6j1A%2B%2FwQ%3D)
A pipeline.
[Edit it on draw.io](https://www.draw.io/?lightbox=1&highlight=0000ff&edit=_blank&layers=1&nav=1&title=a%20pipeline#R5ZbBcoIwEIafhmNnIlFLj5WKvfTkoecIC2QMLBOjaJ%2B%2BQTcCQzv1UutYLiT%2FbjbJt%2F8hHg%2BL%2FUKLKn%2FDBJTns2Tv8RfP90f%2BmNlfoxycMp2elEzLhLRWWMoPIJEWZluZwKaXaBCVkVVfjLEsITY9TWiNdT8tRdXftRIZDIRlLNRQfZeJyUkdMdYGXkFmOW0dTCiwEvE607gtaT%2FP5%2BnxO4UL4WpR%2FiYXCdYdic89HmpEcxoV%2BxBUA9dhO62Lvomez62hNJcsmDymMBUriFmQsnG8eqAKO6G2xMLjEZ3VHBwfe%2ByqGW4MVB6f1bk0sKxE3Gi19YTVclMoOxvZYYqloR77QTOXSoWoUB%2BLccYCFkWU19Gj42f1jdG4BhcpsbSVZsObuqODNrDvSHTzBWABRh9sirOla2fd9pg7C%2Bbd9pImyFbZuVSL1g6I7oWk%2FQHpBHagsCqaG90ZcYqeSd5EB%2Fh%2F8DpFJ9MLyLNrkR8PyFcak21sJJZWn91pEwL%2Bh%2FYfur3H%2FPl2mQ8Af9GGn5lfg%2FEPvg7vnbHz9dPk15jbafs8OsY6j1A%2B%2FwQ%3D)
A pipeline.
Understanding the tradeoffs
Of course, it will depend on your use case. You have to find the balance between time to production, time invested in the pipeline (tests, monitoring, infrastructure…) and validation strictness. StackOverflow stated on one of their presentations that they test the software on their users. While it may work for them, imagine a bank testing the software on the end users. In some cases, the trust is too important to lose. This post will present rock solid pipeline for one development environment and multi-region production environment. If executed correctly, it’s a pipeline which will catch nasty things like memory leakage or minimize blast radius in production.Rock solid pipeline
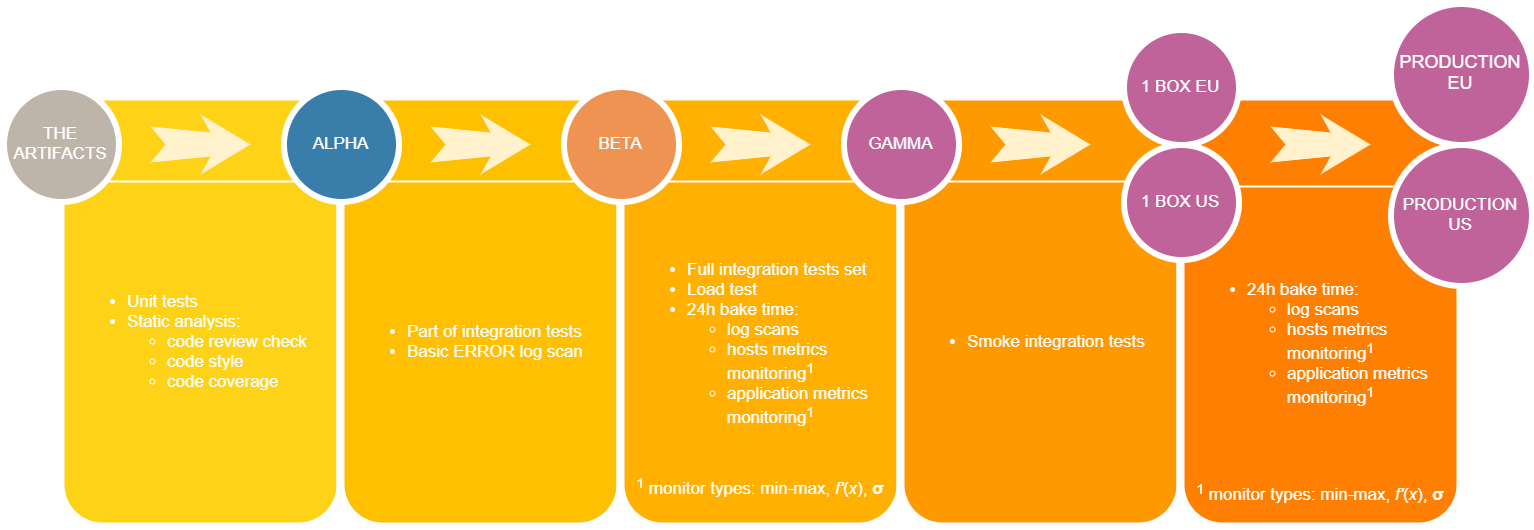 Rock solid pipeline.
Rock solid pipeline.
[Edit it on draw.io](https://www.draw.io/?lightbox=1&highlight=0000ff&edit=_blank&layers=1&nav=1&title=Rock%20solid%20pipeline#R7Vvfc6o4FP5rnN19uB0ggPCoVts7c7vt1HZ2XyNEzRSIA2m1%2B9dvAomGHyrtSGF68aGFQziB833nfEcMAzAJdzcx3KzviI%2BCgaH5uwG4HhiGrusW%2B8ct75nFst3MsIqxLwYdDHP8HxJGTVhfsY%2BS3EBKSEDxJm%2F0SBQhj%2BZsMI7JNj9sSYL8rBu4QiXD3IOBtF5ZB%2Fs%2F2KdreWfyRviBW4RXazG5Y9jZgQX0XlYxeY3EjAMDLNNPdjiE0pe41WQNfbJVTGA6AJOYEJpthbsJCnh0ZeDkefRdXu0AjNc0DNiOzjbTw7MjJ%2Bt1TmY3F6OIqtMd82drPnQW7tI0bNP0AfxhZB7eYPAqJyjOuF1jiuYb6PH9LSNQ%2FhLS2CFf7O3Do%2FEdGpOXPR4OsyxJRAV9DD4CBngVsR2PXT%2BK%2BQAcBBMSkDidG8ym14Y%2B3LtSj6SfyhCIoL2hmKKdYhIhuUEkRDR%2BZ0Pk0aEASdDftISL7YFKhiPGrBUWmUAYoSDwau%2F7AALbEDjUxMSswMQO2JRjH7%2BxzRVNbzszvQZFS4Cl5TnClKciSmgijy7i4nh2fYdTyk7mFFLs8XuMYPCeYHanow86O3WNHitGzHmM3jDa8hKxRt5LzUsT52Zc%2FdApHmHs4EXl1FnMWL7yY8YcNIUMYjSk%2BaTJ0zkiESpwX5hkfgRoyT1wSmNW9kbCHGLf55OMq3L0kJhaMTGVNEyzi%2B83lVuulcsty7TLuQUqcgtoTeSWfb7eBTgNfb54Fepuvdgaw3MlTsDcbHVz89XNAhXVzaxAQG8CAKcEwNPtlBlGj08%2FZ6PJ07yEB3PI%2BohjLK8HSh5MuyIFzinReDY2R%2B5JrJrMIh3kFcosY7jv4nIYSuNFQXTPZ5Fa7FQkfJis9xiVgn60wDEfG%2B453K14C3uVdY3GFZ8RJ8gf8X3ungdIu%2BIIp%2B2tyaeJCPV4kFgsGEqItXR8MjbMLLMmRxS9Ip%2FPlu6sgzQ87zLQs%2BjnoZctrQq9VpG%2BdhPpy3Kl2w3jbKJpZYW9cDqaVqcaRvkd43dSNXPYJVWTAVcQGP16uB11VMyAO7wejdoSM%2BB2SswM0KvZl6mZZXZJzYyqr9qdUrPxF6jZEHRLzcpfEb69mg2tTqlZub8fT5%2B6KmbTmQss0JaY2cNOiRmo0Qr2YnYhMXOMLomZLBmdFbOp62rayTy9ACa6pndKzUCNFuO7qZmugS7JGSg%2F9L0Z3d11Vc%2FGMxu4rX05c61u6VmN5029nl1Iz%2FS9WLUhaFbH5WvmaF8gX4bbpnz1D%2Fa%2FMNuA02K26b%2FhM2Md6MW%2BpOLH6Kb6krKSsavVxvf%2Fsr%2FT574ZqayGIN%2BNAMf8wm6k3Lo%2FPN5fP0%2Beft7%2F3RZoTvdBswpdBLCcMmiyrcyBJo2XbSHLzxNzMD53d8lBp2A03Qp5agzGMmiHatkjVq9aViLWWLXUq54%2FfWrd4gOM%2BbpFsuTeWaRZZ0gxiQaFpYxnlvqNYZKuW5w%2BPt4%2Fsv8BWXHOeDD61Kq%2Fb7zAr0SxCiKe%2BCG%2BzQV%2BunGUdKcYxiAOjpFLSxD99GrZXwT6wlXNMwxzPeDL0F%2F4ulSKQ6Ssr%2F3watoDx%2BtmyZpkN80jj710i0SYkhhHKzk6ed3I4briVjHXnAxuNgGjt4h3g1PWWbrb57Dy82OrOVy1AOM81%2FvE6ROn7cTRgW5eOewDTBtYpm4P28yj4y%2BOnKL%2BPCRpCp3otGrKYM%2BTE7%2BItVphq157qF8vZJnhtHjfoOwNIC3E0Y8Q7gYGm96GIQ92tEg2Ch%2F2BFnuZ9uk3Xdq%2FEOdTrEr5r2DP0sud1XD%2FjpxMYu9%2F8ls4ADl9EVxZpXuFyfx%2BUfi3aXxsLB6z5HPRVUW2009sa5aF9aTuCfxhzVbK7K4ohZfiMVs9%2FBucHpMeQUbTP8H)
The orange cards are validation steps. Once all requirements in validation steps are completed, the change is promoted to the next environment.
The environments
- The artifacts – not really an environment… but the graph looks nice with it :)
- Alpha – environment only for tests purposes. It’s not facing any real traffic. The main purpose is to make the beta environment stable - to catch errors before they will reach development environment and cause cross-team failures.
- Beta – this is the development environment.
- Gamma – again, an environment which isn’t facing any real traffic. It’s very important though, because it is configured identically as the real production environment.
- 1 Box – a small subset of production hosts. Surprise! Not really 1 host… if your service runs on 1000 hosts, you can have, for e.g. 10 of 1 Box hosts.
- Production.
Validation steps
First of all, before deploying the changes anywhere, rudimentary checks can be done. Unit tests can be ran, static analysis can be performed – if code review by right people is done, if the change follows the code style, if the code is covered by unit tests. All checked? Proceed to Alpha.
After Alpha deployment, part of integration tests can be executed. It may be impossible to execute all of the integration tests and keep sensible execution time. Pick the most important ones. As previously written, Alpha is to keep the Beta (development env) stable. By integration tests, I mean all automated test which interact with the environment in any way. While executing the tests, scan the logs for ERRORs. The errors amount has to be kept in reasonable limits. Poorly written code will result in treating the presence of the errors as a normal situation. No issues discovered? Proceed to Beta.
Beta is the development environment. It’s the environment used for demos or manual testing. It’s used heavily through the company, so any issues here will cause time loss for many teams. The change will spend here quite some time and will get tested thoroughly. This is the time to run all integration tests and load tests. Load tests should aim at least production peak volume (scaled per number of hosts). During all this time when different tests are executed and people are using your service, monitor the logs as before. Validate if the logs are produced at all. Use different metrics:
- Host level (CPU usage, thread pool, memory, network IO, disk IO, disk usage, file handles/Inodes number).
- Application level, that is specific to your business, for example:
- Number of invalid sign-ups, average size of sent messages.
- Latency of the downstream APIs, number of requests to the downstream APIs, number of requests to your APIs, latency of your APIs, number of errors returned, number of exceptions thrown.
Monitor those metrics with different kinds of alarms. Most basic one: check if the value is between min/max values. However, there are more powerful and more sophisticated types: first derivative or σ value checks. More on those in the next post. (Edit: published - [Types of alarms - what's beyond min-max checks?](/2017/11/types-of-alarms---whats-beyond-min-max-checks/)) Rigorous tested passed? Proceed to Gamma.
Gamma is a special environment, because it is the first environment with production configuration. The only validation is smoke integration tests, which uses different components of the service to check the configuration. The purpose of those tests is to catch, for example, mistyping in production connection string. Seems to be working? Go to 1-Box.
1-Box, as written previously, is part of your production fleet. It should be a small percentage of production hosts, serving production traffic. Despite obvious reduction of blast radius by number of hosts, there is an additional benefit in some situations. Taking as an example processing messages from a queue, if the faulty 1-Box will take the message and fail, there is a high chance that later on a healthy host will take the message and there will be no customer impact at all. To further reduce blast radius, deploy to one 1-Box region at one time, obviously at off-peak time. After deployment is made, monitor what was monitored in Beta (logs, hosts metrics, application metrics), however now you are performing validation against real production traffic. What’s more, here you can add one more peculiar type of check - compare the Production metrics to 1-Box metrics. This should hopefully reveal any anomaly missed before. After that, go for Production!
Finally, after ~2 days your change arrives in production. We are not perfect, what if critical bug is introduced! Does that mean we have to wait 2 days for a fix? Nope – deploy hotfix as you wish. You can for example skip the two “baking” processes and leave other validation steps in place.
Operational Excellence series
- Intro: What is Software Operational Excellence?
- Deploying: Rock solid pipeline - how to deploy to production comfortably?
- Monitoring&Alarming: Types of alarms - what’s beyond min-max checks?
- Monitoring: What service metrics should be monitored?
- Scaling: (Auto) scaling services by CPU? You are doing it wrong
- Scaling: How do you know the right maximum connections?
- Scaling: How to estimate host fleet size? Why keeping CPU at 30% might NOT be waste of money?
Please note: the views I express are mine alone and they do not necessarily reflect the views of Amazon.com.