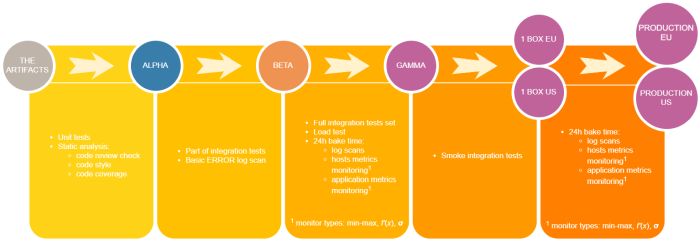
First of all, this post won’t be for people who think developer’s job is to design, write code and test it. It’s far beyond that. One of the important responsibilities is to ship your code to production. How to do that safely?

First of all, this post won’t be for people who think developer’s job is to design, write code and test it. It’s far beyond that. One of the important responsibilities is to ship your code to production. How to do that safely?
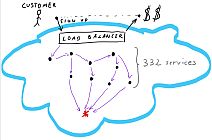
There are certain classes of exciting problems which are surfaced only in a massively distributed systems. This post will be about one of them. It’s rare, it’s real and if it happens, it will take your system down. The root cause, however, is easy to overlook.
It’s surprising how the volume of data is changing around the world in the Internet. Who would have thought 10 years ago that in the future a physical experiment will generate 25 petabytes (26 214 400 GB) of data, yearly? Yes, I’m looking at you, LHC. Times are changing, companies are changing. Everyone is designing for scale a tad different. And that’s good, as it’s important to design for the right scale.
Let’s assume you are considering using Cassandra for logs storage or in general, for time series storage. You are well prepared - asked google extensively. Yet, there is a trap waiting to kill your cluster in few weeks after lunch.

Recently I’ve designed a mechanism to notify external systems (with which we cooperate) about changes in our system. This, obviously, can be done in multiple ways. Let’s look at some considerations on a high level, some questions and how that affects our requirements.