
The nightmare of large distributed systems
There are certain classes of exciting problems which are surfaced only in a massively distributed systems. This post will be about one of them. It’s rare, it’s real and if it happens, it will take your system down. The root cause, however, is easy to overlook.
Assumptions
For this post sake, let's make some assumptions:- Critical service is a service which is crucial from your business perspective, if it goes down, you don't make money, and your customers are furious.
- Your business is a veterinary clinic - or rather - immense, world-wide, distributed, most popular, top-notch veterinary clinic network. You make the money when the clients sign up online for visits. A critical service would be any service, which prevents the client from signing up. Let's call the path of signing up a critical path.
- The massive distributed system is a system consisting of, for example, 333 critical services, each one of them has it's own fleet of 1222 hosts (so in total, there are 406926 hosts running critical services in your system).
- Each critical service is managed by a two pizza team.
All in all, I'm thinking about something like this:
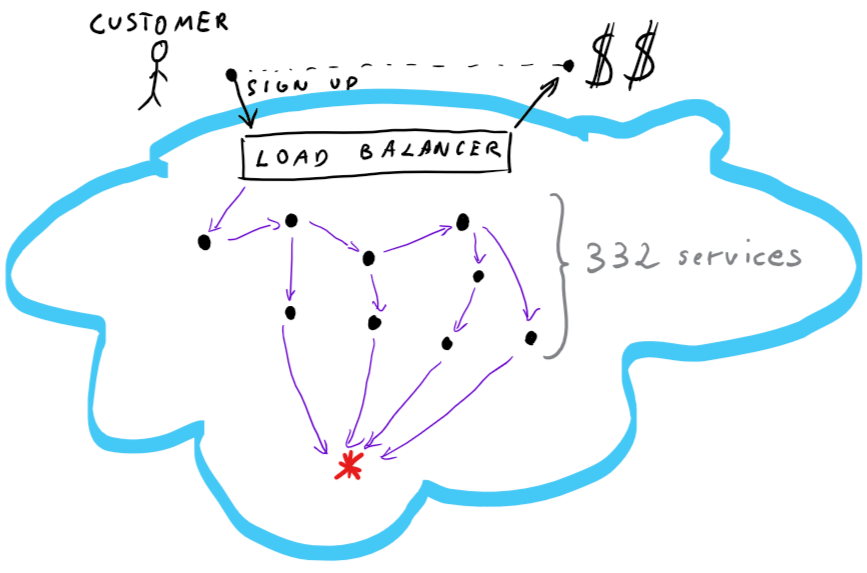 Large distributed system - exponential failure problem
Large distributed system - exponential failure problem
We have a customer, who want's to sign up, the load balancer takes the request, there are 332 healthy services involved, and there is this one red-star service, which is asked 4 times on the critical path. If it goes down, the customer can't sign up. I would compare it to kind of SELECT N+1 problem.
In such a big system, it may happen that a particular, red service will be called 10+ times on a single sign up. The sign up itself may have many steps, and each step may call many services, including our red service, many times. Architecture smell... design smell, you may tell... Yes and no. Think about the scale. 333 critical services, times two pizza teams = around 1333 people involved in just the critical path. Many more involved for non-critical services. I think this situation is inevitable at scale.
Problems
Availability
When the red service is down - that's an obvious situation, easy to spot. What happens if our service has some kind of issues that leads to 90% availability? What is the customer impact, assuming 10 calls made to the red service during sign up? Unfortunately, only 35% of customers will be able to go through the critical path. Why? The first call has 90% chances of success, the second call has also 90% chances of success, but both calls combined have only 0.9*0.9 chances of success. For 10 calls, that will be 0.9^10= ~35%. Unfortunately, in case of "system is down" event, while having enormous amount of alarms going off, tens of services impacted, loosing many customers each second, 10% drop in availability in one service is very, very easy to miss.
Timeouts
The second nasty problem is with the timeouts. The origin of the timeouts can span network problems, hosts problems, code bugs and more. It may happen that random 10% of requests will time out. Let's assume the red service has normally 20ms latency (on average). It's being called 10 times, so total wait time on a single sign up is 200ms. However, with those 10% timeouts, let's say 1.5 seconds each, changes the average latency to 20ms * 0.9 + 1500ms * 0.1 = 168ms. Now the total wait time for the red service is 1680ms. Probably the customer is getting timeouts at this point. It's nasty, because the 10% timeouts issue can be well hidden. For example, it might be a core router which is misbehaving, but still works and our monitoring doesn't discover the packet loss.
TL;DR;
Even tiny issues - like 10% timeouts or 10% availability drop - of only one service out of hundreds on a critical path in large distributed system can take it down.
Please note: the views I express are mine alone and they do not necessarily reflect the views of Amazon.com.