
What is Software Operational Excellence?
It seems that most people know the importance of software design patterns, best practices or continuous integration. While those subjects are important, there is one more equally essential term, which yields only one relevant result link on the first Google page. Meet Operational Excellence.
It doesn’t matter if you are Backblaze storing 400PB (400 000TB) of customers data, a startup having 10 servers or a Tinder having 12 million matches per day - your servers have to be operational 100% of time (ideally). Unfortunately, we don’t live in perfect world. What can fail, will fail. So how to make sure that the servers are running your software constantly, without bugs, with impressive SLA while having time to sleep and develop new features?
Operational Excellence
… is an art of building things correctly and making sure they are running smoothly. The key concept is to balance the technical debt and operation activities with time spent on producing business features.
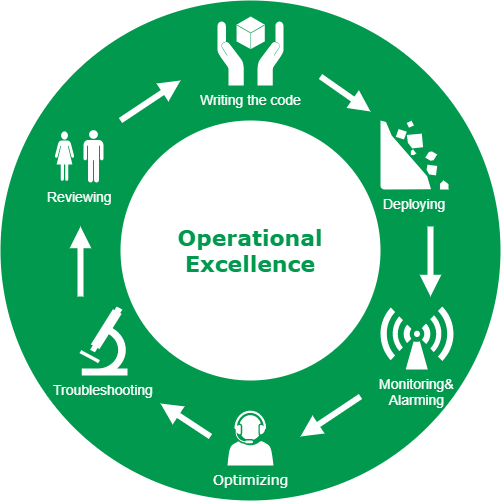 Operational Excellence process
Operational Excellence process
Naturally, everything starts from designing and writing the code (that’s the easy one ;) ).
Then comes the deployment. It’s surprisingly hard to make this step safely and reliably. Read more here: Rock solid pipeline - how to deploy to production comfortably?. The deployment doesn’t always have to be automatic. Sometimes you must perform manual changes. Have the steps written down and reviewed by your peers before executing them.
Third step is to monitor and have the alarms set up properly. Best, if you can figure out alarms that will fire before the customer is affected. Have multiple dashboards showing the health of your service, your dependencies, hosts metrics and infrastructure metrics (load balancer, network, etc.). The more metrics you have, the better decisions based on tangible data you can make. Have a procedure how to respond in case of an alarm. The more documentation, the better because at 4AM you won’t be at your best.
Having the metrics, you can consider optimizing some areas. Look for API degradations. Set the bar high - consider monitoring 99.9th percentile of some metrics. They may show some problems for peculiar customers.
If anything will happen, mitigate the issue as quickly as possible, but find the root cause later. If you don’t know the root cause, how can you make sure the problem won’t come back again? Dive deep and understand the situation. Ask as many “whys” as needed to get to the real problem. How can you add more details to logging/metrics/dashboard/documentation to find the mitigation and root cause in the future faster?
Have review meetings. Weekly/monthly - it’s up to you. What were the problems, what was the root cause, where is the technical debt, how can you protect yourself against the next such an event? Determine actions, set the deadlines.
All of that? What for?
Mastering the operational excellence will decrease the load on the software engineers, allow them to focus on the business features implementation and improve their work satisfaction greatly. There is nothing more fulfilling than a smoothly running system.
Operational Excellence series
- Intro: What is Software Operational Excellence?
- Deploying: Rock solid pipeline - how to deploy to production comfortably?
- Monitoring&Alarming: Types of alarms - what’s beyond min-max checks?
- Monitoring: What service metrics should be monitored?
- Scaling: (Auto) scaling services by CPU? You are doing it wrong
- Scaling: How do you know the right maximum connections?
- Scaling: How to estimate host fleet size? Why keeping CPU at 30% might NOT be waste of money?
Please note: the views I express are mine alone and they do not necessarily reflect the views of Amazon.com.