
How to estimate host fleet size? Why keeping CPU at 30% might NOT be waste of money?
What does maximum-connections, CPU autoscaling, money and distributed systems have in common? Find out.
You are given a task: how many servers should you get to run your service, given that maximum allowed average CPU usage can be 80%.
Figure out the real problem
So far the problem is as follows:
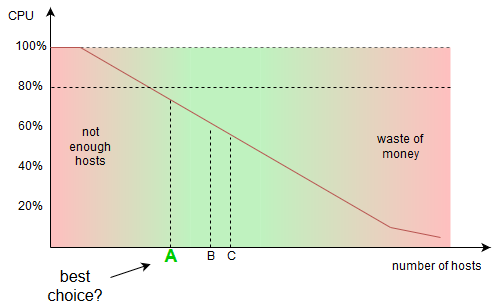
With increasing number of hosts in a fleet, the CPU utilization should be successively smaller. The proportion and exact curve will be different for each system (it can be non-linear too), however as a simplification let’s assume it looks like on the graph. At this point, one can pick number A, B or C of hosts. All three points are matching the task conditions, so obviously the best would be pick A, which already has some buffer. However, is that all?
Taking maximum connections into consideration
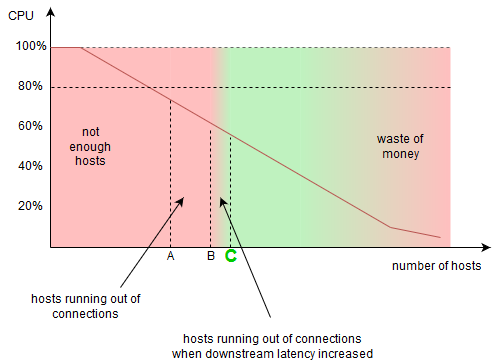
In previous post, How do you know the right maximum connections?, we estimated how many connections one server can handle - so called maximum-connections. It can happen, that when we use “A” number of hosts, all of them will get many connections from clients, finally exhausting allowed number of connections - exhausting the connection pools on the servers. New clients will not be able to connect - our service will be unavailable for them, thus we failed the task. So will be B or C better?
Math model - Litte’s Law
There is the Litte’s Law which basically says:
For example, let’s say you have 1000 requests per second hitting your service (load balancer), each is taking on average 300ms, therefore at any given time you are having 300 concurrent requests in your service.How many hosts do you need now?
It seems the answer now is:
Challenge 1: How do you know your latency? What latency is it (average, nth percentile)?
This depends highly on a use case, as shown in this post, situation 2. You have to make decision, which latency you want to withstand on a prolonged manner. The most optimistic situation is taking the average, as there are a lot of requests over the average. The most pessimistic would be taking the timeout value for downstream dependencies. If the dependency is not critical, one can use circuit breaker to avoid running out of connections. Let’s say ended up with increasing fleet size to B for normal latency, and we have to use actually C, for a slightly degraded downstream latency:
Challenge 2: Cross region redundancy
Unfortunately, things get even worse (from CPU utilization perspective), if we want to make our system truly available and redundant. If we have the service deployed in two datacenters, and we want to avoid downtime when one datacenter goes down, we have to double the number of hosts. If the service is deployed in three centers, and again, we want to avoid downtime when one datacenter goes down, we have to over scale “just” 1 out of 3 = 33%. Let’s assume we want to have “two out of three” availability, thus we ended up with pretty low CPU utilization:
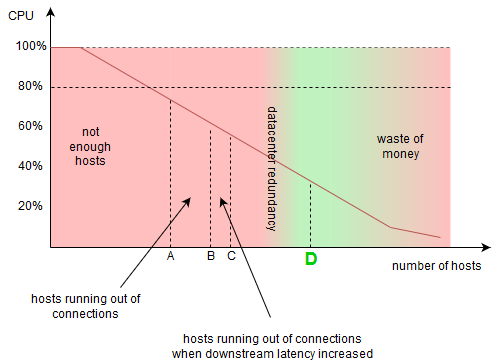
Low CPU utilization
The reasons above are the exactly the reasons why you might sometimes see the CPU utilization at 30~40% level. It’s not necessarily the waste of money.
Operational Excellence series
- Intro: What is Software Operational Excellence?
- Deploying: Rock solid pipeline - how to deploy to production comfortably?
- Monitoring&Alarming: Types of alarms - what’s beyond min-max checks?
- Monitoring: What service metrics should be monitored?
- Scaling: (Auto) scaling services by CPU? You are doing it wrong
- Scaling: How do you know the right maximum connections?
- Scaling: How to estimate host fleet size? Why keeping CPU at 30% might NOT be waste of money?
Please note: the views I express are mine alone and they do not necessarily reflect the views of Amazon.com.