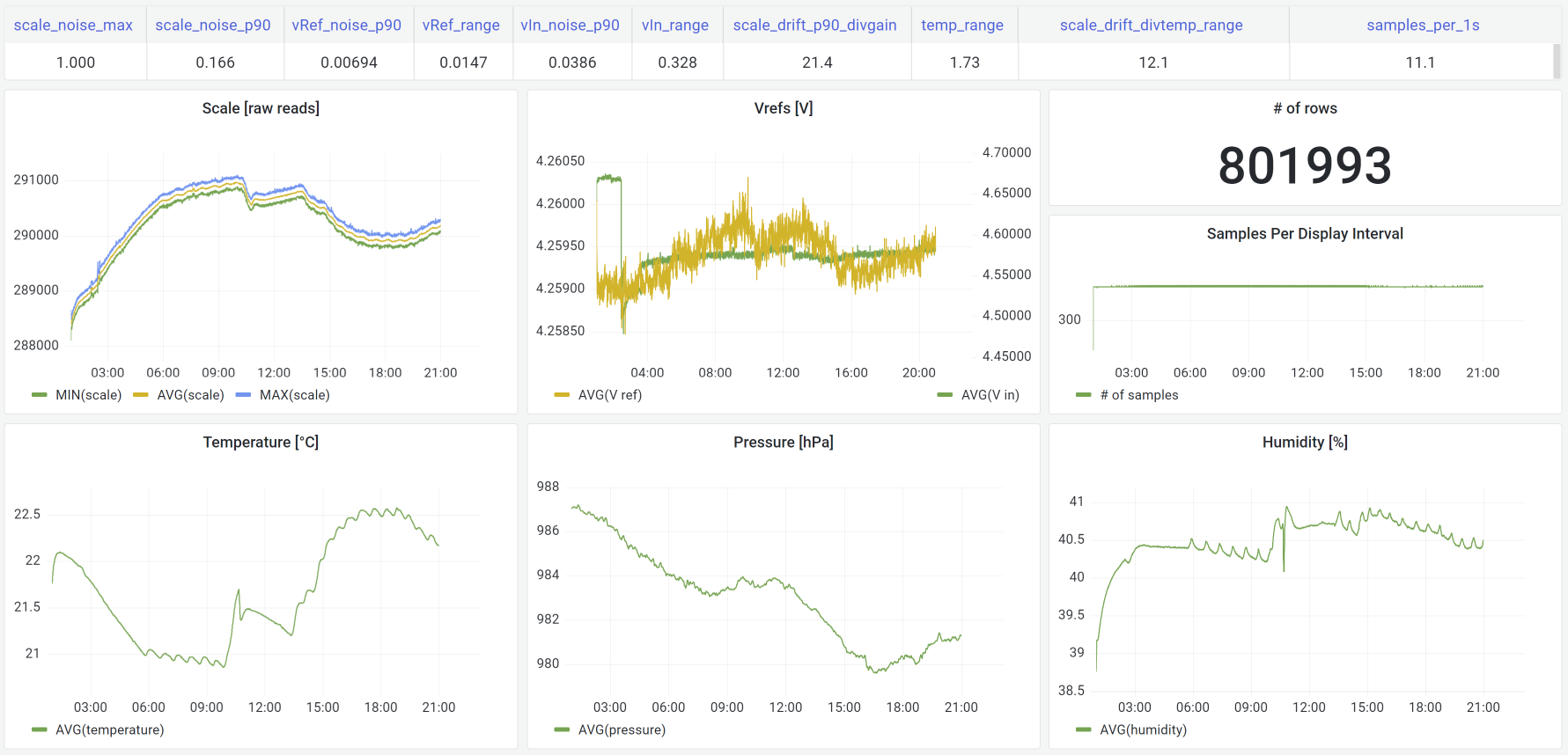
Collecting weight scale data in my… fridge.


Collecting weight scale data in my… fridge.
Chasing 0.4g of missing food in my cat feeder.
Start here to read about the ultimate cat feeder.

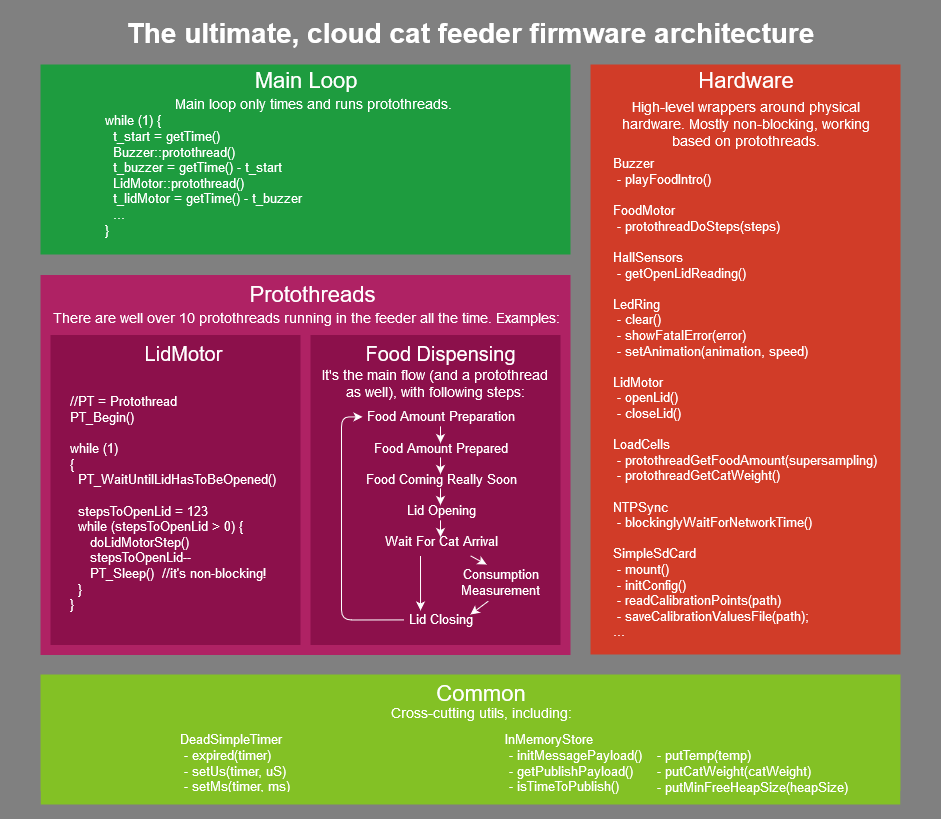
How do you write a fairly complex Arduino project? Are there any best practices? …and for those who waited, the cloud cat feeder source code is now publicly available.
Dirty cheap PCB will make your life MUCH easier.

Around 500 MB of 3D models in ~50 STL files, plus Fusion 360 archive made available under Open Source license.
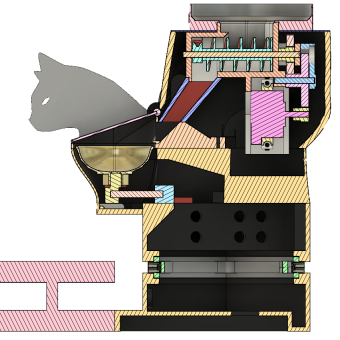
The ultimate cat feeder is done. Watch the demo and see why so many people like it!
