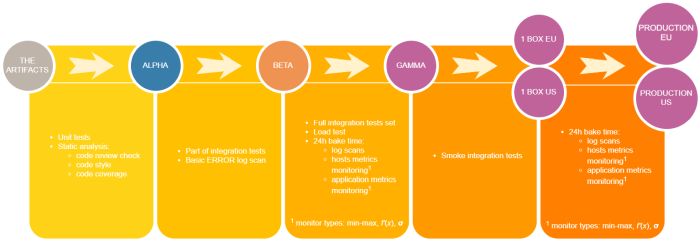
It seems that most people know the importance of software design patterns, best practices or continuous integration. While those subjects are important, there is one more equally essential term, which yields only one relevant result link on the first Google page. Meet Operational Excellence.