
(Auto) scaling services by CPU? You are doing it wrong
Bob is a very successful guy. He is auto scaling his service by automatically adding hosts when the CPU increases, and he is removing them when CPU goes down. Dear Bob, there is a trap waiting for you around the corner.
What does it mean to auto scale the service based on XXX usage?
Firstly, let’s cover the basics. Scaling the service means giving (or removing) resources for a component in your system. For example, adding servers (hosts) to a load balancer, which exposes particular application… or adding more instances of a container to a group… or bringing up a bigger server. Auto scaling means doing that automatically. Whenever metric increases - for example - average CPU usage will be higher than 50% for 2 minutes, add 2 hosts under a load balancer. This way, by monitoring key host health indicators - like CPU, memory, disk usage, one can avoid exhaustion of resources due to increased traffic.
Why shouldn’t you rely only on CPU auto scaling?
Yes, there are also other obvious dimensions of scaling: What service metrics should be monitored?. However, that’s not all.
Limiting the number of concurrent connections
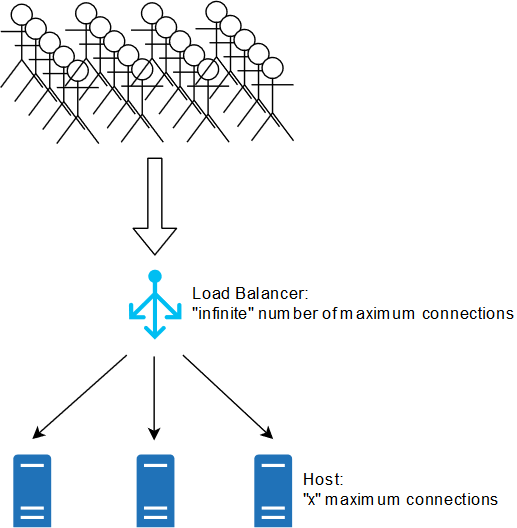 Hosts under load balancer
Hosts under load balancer
Every host should have limited maximum number of concurrent client connections to it at any given type. Why?
Situation 1
Consider a host without maximum connections limit. Let’s assume you have a fleet of 100 hosts, each serving around 10 requests per second. CPU on average is on 20% level.
Somebody just posted your website on reddit.com, “the front page of the internet”. “Some” of 542 million monthly reddit visitors go to your website. In the first minute, your hosts are slammed with huge stream of traffic. Each host is now serving 25 requests per second. CPU increased to 70%. Auto scaling is kicking in. 20 hosts are just being started and they will be ready in 15 minutes. Unfortunately, in the second minute, your hosts are overloaded. Theirs CPU is constantly on 100%. Some of them serve concurrently thousands of requests, timing out every request they get. What’s worse, they are timing out on load balancer health checks as well. So what load balancer does? It kills happily your hosts one by one, as it thinks hosts are unhealthy, replacing them with new hosts. Fast forward the nightmare 13 minutes. 20 new hosts arrived, they are added under load balancer. They served few requests, but then the situation repeats. They get too many requests, they are timing out, CPU stays at 100% making them useless. How to fix the death loop?
Situation 2
The beginning is almost the same. Consider a host without maximum connections limit. Let’s assume you have a fleet of 100 hosts, each serving around 10 requests per second. The average request latency to your service is 30ms. CPU on average is on healthy 50% level.
Your database just started to have some problems. Instead of average 10ms query time, it has now 6200ms, due to stale table statistics. Not convinced? The AWS S3, which your service heavily use, is having problems and it’s timing out after 6200ms, instead of normal few millisecond response times. As the response time from downstream services is much bigger, the average request takes 30ms-10ms+6200ms=6220ms. Having 10 requests per second stream hitting your host, let’s calculate how many requests per second does your host have to handle now concurrently: 10 request from first second, 10 request from 2nd second, 10 from 3rd, 10 from 4th, 10 from 5th, 10 from 6th, and around 2 from fifth, that is 62 concurrent requests, instead of 10. If there was 50% CPU utilization, probably now it’s around 300%. Just kidding, 100% is bad enough. Adding more hosts improves the situation, however what’s the point? Your service can’t function without the database or S3! How to fix it?
The answer is…
Homework! How to adjust maximum concurrent connections (per host) limit? What should be the limit? 1? 10? 42? How did you get that number?
Operational Excellence series
- Intro: What is Software Operational Excellence?
- Deploying: Rock solid pipeline - how to deploy to production comfortably?
- Monitoring&Alarming: Types of alarms - what’s beyond min-max checks?
- Monitoring: What service metrics should be monitored?
- Scaling: (Auto) scaling services by CPU? You are doing it wrong
- Scaling: How do you know the right maximum connections?
- Scaling: How to estimate host fleet size? Why keeping CPU at 30% might NOT be waste of money?
Please note: the views I express are mine alone and they do not necessarily reflect the views of Amazon.com.