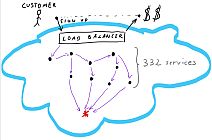
There are certain classes of exciting problems which are surfaced only in a massively distributed systems. This post will be about one of them. It’s rare, it’s real and if it happens, it will take your system down. The root cause, however, is easy to overlook.